- Docs Home
- About TiDB
- Quick Start
- Develop
- Overview
- Quick Start
- Build a TiDB Cluster in TiDB Cloud (Developer Tier)
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Third-party Support
- Deploy
- Software and Hardware Requirements
- Environment Configuration Checklist
- Plan Cluster Topology
- Install and Start
- Verify Cluster Status
- Test Cluster Performance
- Migrate
- Overview
- Migration Tools
- Migration Scenarios
- Migrate from Aurora
- Migrate MySQL of Small Datasets
- Migrate MySQL of Large Datasets
- Migrate and Merge MySQL Shards of Small Datasets
- Migrate and Merge MySQL Shards of Large Datasets
- Migrate from CSV Files
- Migrate from SQL Files
- Migrate from One TiDB Cluster to Another TiDB Cluster
- Migrate from TiDB to MySQL-compatible Databases
- Advanced Migration
- Integrate
- Overview
- Integration Scenarios
- Maintain
- Monitor and Alert
- Troubleshoot
- TiDB Troubleshooting Map
- Identify Slow Queries
- Analyze Slow Queries
- SQL Diagnostics
- Identify Expensive Queries Using Top SQL
- Identify Expensive Queries Using Logs
- Statement Summary Tables
- Troubleshoot Hotspot Issues
- Troubleshoot Increased Read and Write Latency
- Save and Restore the On-Site Information of a Cluster
- Troubleshoot Cluster Setup
- Troubleshoot High Disk I/O Usage
- Troubleshoot Lock Conflicts
- Troubleshoot TiFlash
- Troubleshoot Write Conflicts in Optimistic Transactions
- Troubleshoot Inconsistency Between Data and Indexes
- Performance Tuning
- Tuning Guide
- Configuration Tuning
- System Tuning
- Software Tuning
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- Tutorials
- TiDB Tools
- Overview
- Use Cases
- Download
- TiUP
- Documentation Map
- Overview
- Terminology and Concepts
- Manage TiUP Components
- FAQ
- Troubleshooting Guide
- Command Reference
- Overview
- TiUP Commands
- TiUP Cluster Commands
- Overview
- tiup cluster audit
- tiup cluster check
- tiup cluster clean
- tiup cluster deploy
- tiup cluster destroy
- tiup cluster disable
- tiup cluster display
- tiup cluster edit-config
- tiup cluster enable
- tiup cluster help
- tiup cluster import
- tiup cluster list
- tiup cluster patch
- tiup cluster prune
- tiup cluster reload
- tiup cluster rename
- tiup cluster replay
- tiup cluster restart
- tiup cluster scale-in
- tiup cluster scale-out
- tiup cluster start
- tiup cluster stop
- tiup cluster template
- tiup cluster upgrade
- TiUP DM Commands
- Overview
- tiup dm audit
- tiup dm deploy
- tiup dm destroy
- tiup dm disable
- tiup dm display
- tiup dm edit-config
- tiup dm enable
- tiup dm help
- tiup dm import
- tiup dm list
- tiup dm patch
- tiup dm prune
- tiup dm reload
- tiup dm replay
- tiup dm restart
- tiup dm scale-in
- tiup dm scale-out
- tiup dm start
- tiup dm stop
- tiup dm template
- tiup dm upgrade
- TiDB Cluster Topology Reference
- DM Cluster Topology Reference
- Mirror Reference Guide
- TiUP Components
- PingCAP Clinic Diagnostic Service
- TiDB Operator
- Dumpling
- TiDB Lightning
- TiDB Data Migration
- About TiDB Data Migration
- Architecture
- Quick Start
- Deploy a DM cluster
- Tutorials
- Advanced Tutorials
- Maintain
- Cluster Upgrade
- Tools
- Performance Tuning
- Manage Data Sources
- Manage Tasks
- Export and Import Data Sources and Task Configurations of Clusters
- Handle Alerts
- Daily Check
- Reference
- Architecture
- Command Line
- Configuration Files
- OpenAPI
- Compatibility Catalog
- Secure
- Monitoring and Alerts
- Error Codes
- Glossary
- Example
- Troubleshoot
- Release Notes
- Backup & Restore (BR)
- Point-in-Time Recovery
- TiDB Binlog
- TiCDC
- Dumpling
- sync-diff-inspector
- TiSpark
- Reference
- Cluster Architecture
- Key Monitoring Metrics
- Secure
- Privileges
- SQL
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ADMIN SHOW TELEMETRYALTER DATABASEALTER INDEXALTER INSTANCEALTER PLACEMENT POLICYALTER TABLEALTER TABLE COMPACTALTER TABLE SET TIFLASH MODEALTER USERANALYZE TABLEBACKUPBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE PLACEMENT POLICYCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP PLACEMENT POLICYDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]LOAD DATALOAD STATSMODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACERESTOREREVOKE <privileges>REVOKE <role>ROLLBACKSAVEPOINTSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [BACKUPS|RESTORES]SHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CONFIGSHOW CREATE PLACEMENT POLICYSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLACEMENTSHOW PLACEMENT FORSHOW PLACEMENT LABELSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Garbage Collection (GC)
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Placement Rules in SQL
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_CONFIGCLUSTER_HARDWARECLUSTER_INFOCLUSTER_LOADCLUSTER_LOGCLUSTER_SYSTEMINFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESINSPECTION_RESULTINSPECTION_RULESINSPECTION_SUMMARYKEY_COLUMN_USAGEMETRICS_SUMMARYMETRICS_TABLESPARTITIONSPLACEMENT_POLICIESPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVARIABLES_INFOVIEWS
METRICS_SCHEMA
- UI
- TiDB Dashboard
- Overview
- Maintain
- Access
- Overview Page
- Cluster Info Page
- Top SQL Page
- Key Visualizer Page
- Metrics Relation Graph
- SQL Statements Analysis
- Slow Queries Page
- Cluster Diagnostics
- Monitoring Page
- Search Logs Page
- Instance Profiling
- Session Management and Configuration
- FAQ
- CLI
- Command Line Flags
- Configuration File Parameters
- System Variables
- Storage Engines
- Telemetry
- Errors Codes
- Table Filter
- Schedule Replicas by Topology Labels
- FAQs
- Release Notes
- All Releases
- Release Timeline
- TiDB Versioning
- TiDB Installation Packages
- v6.2
- v6.1
- v6.0
- v5.4
- v5.3
- v5.2
- v5.1
- v5.0
- v4.0
- v3.1
- v3.0
- v2.1
- v2.0
- v1.0
- Glossary
Connection Pools and Connection Parameters
This document describes how to configure connection pools and connection parameters when you use a driver or ORM framework to connect to TiDB.
If you are interested in more tips about Java application development, see Best Practices for Developing Java Applications with TiDB
If you are interested in more tips about Java application development, see Best Practices for Developing Java Applications with TiDB
Connection pool
Building TiDB (MySQL) connections is relatively expensive (for OLTP scenarios at least). Because in addition to building a TCP connection, connection authentication is also required. Therefore, the client usually saves the TiDB (MySQL) connections to the connection pool for reuse.
Java has many connection pool implementations such as HikariCP, tomcat-jdbc, druid, c3p0, and dbcp. TiDB does not limit which connection pool you use, so you can choose whichever you like for your application.
Configure the number of connections
It is a common practice that the connection pool size is well adjusted according to the application's own needs. Take HikariCP as an example:
- maximumPoolSize: The maximum number of connections in the connection pool. If this value is too large, TiDB consumes resources to maintain useless connections. If this value is too small, the application gets slow connections. Therefore, you need to configure this value according to your application characteristics. For details, see About Pool Sizing.
- minimumIdle: The minimum number of idle connections in the connection pool. It is mainly used to reserve some connections to respond to sudden requests when the application is idle. You also need to configure it according to your application characteristics.
The application needs to return the connection after finishing using it. It is recommended that the application uses the corresponding connection pool monitoring (such as metricRegistry) to locate connection pool issues in time.
Probe configuration
The connection pool maintains persistent connections to TiDB. TiDB does not proactively close client connections by default (unless an error is reported), but generally, there are also network proxies such as LVS or HAProxy between the client and TiDB. Usually, these proxies proactively clean up connections that are idle for a certain period. In addition to paying attention to the idle configuration of the proxies, the connection pool also needs to keep alive or probe connections.
If you often see the following error in your Java application:
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
If n in n milliseconds ago is 0 or a very small value, it is usually because the executed SQL operation causes TiDB to exit abnormally. To find the cause, it is recommended to check the TiDB stderr log.
If n is a very large value (such as 3600000 in the above example), it is likely that this connection was idle for a long time and then closed by the proxy. The usual solution is to increase the value of the proxy's idle configuration and allow the connection pool to:
- Check whether the connection is available before using the connection every time.
- Regularly check whether the connection is available using a separate thread.
- Send a test query regularly to keep alive connections.
Different connection pool implementations might support one or more of the above methods. You can check your connection pool documentation to find the corresponding configuration.
Formulas based on experience
According to the About Pool Sizing article of HikariCP, if you have no idea about how to set a proper size for the database connection pool, you can get started with a formula based on experience. Then, based on the performance result of the pool size calculated from the formula, you can further adjust the size to achieve the best performance.
The formula based on experience is as follows:
connections = ((core_count * 2) + effective_spindle_count)
The description of each parameter in the formula is as follows:
- connections: the size of connections obtained.
- core_count: the number of CPU cores.
- effective_spindle_count: the number of hard drives (not SSD). Because each spinning hard disk can be called a spindle. For example, if you are using a server with a RAID of 16 disks, the effective_spindle_count should be 16. Because HDD usually can handle only one request at a time, the formula here is actually measuring how many concurrent I/O requests your server can manage.
In particular, pay attention to the following note below the formula.
A formula which has held up pretty well across a lot of benchmarks for years is that for optimal throughput the number of active connections should be somewhere near ((core_count * 2) + effective_spindle_count). Core count should not include HT threads, even if hyperthreading is enabled. Effective spindle count is zero if the active data set is fully cached, and approaches the actual number of spindles as the cache hit rate falls. ... There hasn't been any analysis so far regarding how well the formula works with SSDs.
This note indicates that:
- core_count is the number of physical cores, regardless of whether you enable Hyper-Threading or not.
- When data is fully cached, you need to set effective_spindle_count to
0. As the hit rate of cache decreases, the count is closer to the actual number ofHDD. - Whether the formula works for SSD is not tested and unknown.
When using SSDs, it is recommended that you use the following formula based on experience instead:
connections = (number of cores * 4)
Therefore, you can set the maximum connection size of the initial connection pool to cores * 4 in the case of SSDs and further adjust the size to tune the performance.
Tuning direction
As you can see, a size calculated from the formulas based on experience is just a recommended base value. To get the optimal size on a specific machine, you need to try other values around the base value and test the performance.
Here are some basic rules to help you get the optimal size:
- If your network or storage latency is high, increase your maximum number of connections to reduce the latency waiting time. Once a thread is blocked by latency, other threads can take over and continue processing.
- If you have multiple services deployed on your server and each service has a separate connection pool, consider the sum of the maximum number of connections to all connection pools.
Connection parameters
Java applications can be encapsulated with various frameworks. In most of the frameworks, JDBC API is called on the bottommost level to interact with the database server. For JDBC, it is recommended that you focus on the following things:
- JDBC API usage choice
- API Implementer's parameter configuration
JDBC API
For JDBC API usage, see JDBC official tutorial. This section covers the usage of several important APIs.
Use Prepare API
For OLTP (Online Transactional Processing) scenarios, the SQL statements sent by the program to the database are several types that can be exhausted after removing parameter changes. Therefore, it is recommended to use Prepared Statements instead of regular execution from a text file and reuse Prepared Statements to execute directly. This avoids the overhead of repeatedly parsing and generating SQL execution plans in TiDB.
At present, most upper-level frameworks call the Prepare API for SQL execution. If you use the JDBC API directly for development, pay attention to choosing the Prepare API.
In addition, with the default implementation of MySQL Connector/J, only client-side statements are preprocessed, and the statements are sent to the server in a text file after ? is replaced on the client. Therefore, in addition to using the Prepare API, you also need to configure useServerPrepStmts = true in JDBC connection parameters before you perform statement preprocessing on the TiDB server. For detailed parameter configuration, see MySQL JDBC parameters.
Use Batch API
For batch inserts, you can use the addBatch/executeBatch API. The addBatch() method is used to cache multiple SQL statements first on the client, and then send them to the database server together when calling the executeBatch method.
In the default MySQL Connector/J implementation, the sending time of the SQL statements that are added to batch with addBatch() is delayed to the time when executeBatch() is called, but the statements will still be sent one by one during the actual network transfer. Therefore, this method usually does not reduce the amount of communication overhead.
If you want to batch network transfer, you need to configure rewriteBatchedStatements = true in the JDBC connection parameters. For the detailed parameter configuration, see Batch-related parameters.
Use StreamingResult to get the execution result
In most scenarios, to improve execution efficiency, JDBC obtains query results in advance and saves them in client memory by default. But when the query returns a super large result set, the client often wants the database server to reduce the number of records returned at a time and waits until the client's memory is ready and it requests for the next batch.
Usually, there are two kinds of processing methods in JDBC:
Set FetchSize to
Integer.MIN_VALUEto ensure that the client does not cache. The client will read the execution result from the network connection throughStreamingResult.When the client uses the streaming read method, it needs to finish reading or close
resultsetbefore continuing to use the statement to make a query. Otherwise, the errorNo statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.is returned.To avoid such an error in queries before the client finishes reading or closes
resultset, you can add theclobberStreamingResults=trueparameter in the URL. Then,resultsetis automatically closed but the result set to be read in the previous streaming query is lost.To use Cursor Fetch, first set
FetchSizeas a positive integer and configureuseCursorFetch=truein the JDBC URL.
TiDB supports both methods, but it is preferred that you use the first method, because it is a simpler implementation and has a better execution efficiency.
MySQL JDBC parameters
JDBC usually provides implementation-related configurations in the form of JDBC URL parameters. This section introduces MySQL Connector/J's parameter configurations (If you use MariaDB, see MariaDB's parameter configurations). Because this document cannot cover all configuration items, it mainly focuses on several parameters that might affect performance.
Prepare-related parameters
This section introduces parameters related to Prepare.
useServerPrepStmts
useServerPrepStmts is set to
falseby default, that is, even if you use the Prepare API, the "prepare" operation will be done only on the client. To avoid the parsing overhead of the server, if the same SQL statement uses the Prepare API multiple times, it is recommended to set this configuration totrue.To verify that this setting already takes effect, you can do:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > QPS By Instance.
- If
COM_QUERYis replaced byCOM_STMT_EXECUTEorCOM_STMT_PREPAREin the request, it means this setting already takes effect.
cachePrepStmts
Although
useServerPrepStmts=trueallows the server to execute Prepared Statements, by default, the client closes the Prepared Statements after each execution and does not reuse them. This means that the "prepare" operation is not even as efficient as text file execution. To solve this, it is recommended that after settinguseServerPrepStmts=true, you should also configurecachePrepStmts=true. This allows the client to cache Prepared Statements.To verify that this setting already takes effect, you can do:
Go to TiDB monitoring dashboard and view the request command type through Query Summary > QPS By Instance.
If the number of
COM_STMT_EXECUTEin the request is far more than the number ofCOM_STMT_PREPARE, it means this setting already takes effect.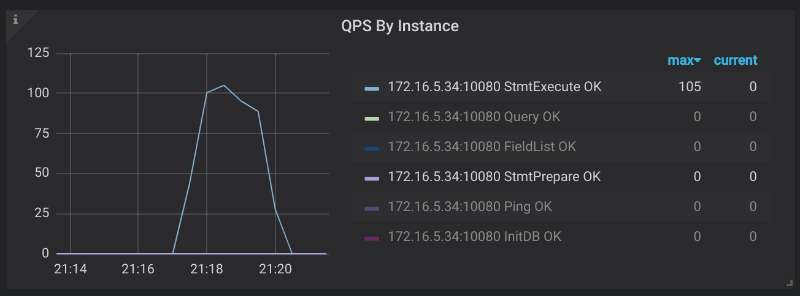
In addition, configuring
useConfigs=maxPerformancewill configure multiple parameters at the same time, includingcachePrepStmts=true.
prepStmtCacheSqlLimit
After configuring
cachePrepStmts, also pay attention to theprepStmtCacheSqlLimitconfiguration (the default value is256). This configuration controls the maximum length of the Prepared Statements cached on the client.The Prepared Statements that exceed this maximum length will not be cached, so they cannot be reused. In this case, you may consider increasing the value of this configuration depending on the actual SQL length of the application.
You need to check whether this setting is too small if you:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > QPS By Instance.
- And find that
cachePrepStmts=truehas been configured, butCOM_STMT_PREPAREis still mostly equal toCOM_STMT_EXECUTEandCOM_STMT_CLOSEexists.
prepStmtCacheSize
prepStmtCacheSize controls the number of cached Prepared Statements (the default value is
25). If your application requires "preparing" many types of SQL statements and wants to reuse Prepared Statements, you can increase this value.To verify that this setting already takes effect, you can do:
- Go to TiDB monitoring dashboard and view the request command type through Query Summary > QPS By Instance.
- If the number of
COM_STMT_EXECUTEin the request is far more than the number ofCOM_STMT_PREPARE, it means this setting already takes effect.
Batch-related parameters
While processing batch writes, it is recommended to configure rewriteBatchedStatements=true. After using addBatch() or executeBatch(), JDBC still sends SQL one by one by default, for example:
pstmt = prepare("INSERT INTO `t` (a) values(?)");
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
Although Batch methods are used, the SQL statements sent to TiDB are still individual INSERT statements:
INSERT INTO `t` (`a`) VALUES(10);
INSERT INTO `t` (`a`) VALUES(11);
INSERT INTO `t` (`a`) VALUES(12);
But if you set rewriteBatchedStatements=true, the SQL statements sent to TiDB will be a single INSERT statement:
INSERT INTO `t` (`a`) values(10),(11),(12);
Note that the rewrite of the INSERT statements is to concatenate the values after multiple "values" keywords into a whole SQL statement. If the INSERT statements have other differences, they cannot be rewritten, for example:
INSERT INTO `t` (`a`) VALUES (10) ON DUPLICATE KEY UPDATE `a` = 10;
INSERT INTO `t` (`a`) VALUES (11) ON DUPLICATE KEY UPDATE `a` = 11;
INSERT INTO `t` (`a`) VALUES (12) ON DUPLICATE KEY UPDATE `a` = 12;
The above INSERT statements cannot be rewritten into one statement. But if you change the three statements into the following ones:
INSERT INTO `t` (`a`) VALUES (10) ON DUPLICATE KEY UPDATE `a` = VALUES(`a`);
INSERT INTO `t` (`a`) VALUES (11) ON DUPLICATE KEY UPDATE `a` = VALUES(`a`);
INSERT INTO `t` (`a`) VALUES (12) ON DUPLICATE KEY UPDATE `a` = VALUES(`a`);
Then they meet the rewrite requirement. The above INSERT statements will be rewritten into the following one statement:
INSERT INTO `t` (`a`) VALUES (10), (11), (12) ON DUPLICATE KEY UPDATE a = VALUES(`a`);
If there are three or more updates during the batch update, the SQL statements will be rewritten and sent as multiple queries. This effectively reduces the client-to-server request overhead, but the side effect is that a larger SQL statement is generated. For example:
UPDATE `t` SET `a` = 10 WHERE `id` = 1; UPDATE `t` SET `a` = 11 WHERE `id` = 2; UPDATE `t` SET `a` = 12 WHERE `id` = 3;
In addition, because of a client bug, if you want to configure rewriteBatchedStatements=true and useServerPrepStmts=true during batch update, it is recommended that you also configure the allowMultiQueries=true parameter to avoid this bug.
Integrate parameters
Through monitoring, you might notice that although the application only performs INSERT operations to the TiDB cluster, there are a lot of redundant SELECT statements. Usually this happens because JDBC sends some SQL statements to query the settings, for example, select @@session.transaction_read_only. These SQL statements are useless for TiDB, so it is recommended that you configure useConfigs=maxPerformance to avoid extra overhead.
useConfigs=maxPerformance configuration includes a group of configurations:
cacheServerConfiguration=true
useLocalSessionState=true
elideSetAutoCommits=true
alwaysSendSetIsolation=false
enableQueryTimeouts=false
After it is configured, you can check the monitoring to see a decreased number of SELECT statements.
Timeout-related parameters
TiDB provides two MySQL-compatible parameters to control the timeout: wait_timeout and max_execution_time. These two parameters respectively control the connection idle timeout with the Java application and the timeout of the SQL execution in the connection; that is to say, these parameters control the longest idle time and the longest busy time for the connection between TiDB and the Java application. Since TiDB v5.4, the default value of wait_timeout is 28800 seconds, which is 8 hours. For TiDB versions earlier than v5.4, the default value is 0, which means the timeout is unlimited. The default value of max_execution_time is 0, which means the maximum execution time of a SQL statement is unlimited.
However, in an actual production environment, idle connections and SQL statements with excessively long execution time negatively affect databases and applications. To avoid idle connections and SQL statements that are executed for too long, you can configure these two parameters in your application's connection string. For example, set sessionVariables=wait_timeout=3600 (1 hour) and sessionVariables=max_execution_time=300000 (5 minutes).