- Docs Home
- About TiDB
- Quick Start
- Develop
- Overview
- Quick Start
- Build a TiDB Cluster in TiDB Cloud (Developer Tier)
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Third-party Support
- Deploy
- Software and Hardware Requirements
- Environment Configuration Checklist
- Plan Cluster Topology
- Install and Start
- Verify Cluster Status
- Test Cluster Performance
- Migrate
- Overview
- Migration Tools
- Migration Scenarios
- Migrate from Aurora
- Migrate MySQL of Small Datasets
- Migrate MySQL of Large Datasets
- Migrate and Merge MySQL Shards of Small Datasets
- Migrate and Merge MySQL Shards of Large Datasets
- Migrate from CSV Files
- Migrate from SQL Files
- Migrate from One TiDB Cluster to Another TiDB Cluster
- Migrate from TiDB to MySQL-compatible Databases
- Advanced Migration
- Integrate
- Overview
- Integration Scenarios
- Maintain
- Monitor and Alert
- Troubleshoot
- TiDB Troubleshooting Map
- Identify Slow Queries
- Analyze Slow Queries
- SQL Diagnostics
- Identify Expensive Queries Using Top SQL
- Identify Expensive Queries Using Logs
- Statement Summary Tables
- Troubleshoot Hotspot Issues
- Troubleshoot Increased Read and Write Latency
- Save and Restore the On-Site Information of a Cluster
- Troubleshoot Cluster Setup
- Troubleshoot High Disk I/O Usage
- Troubleshoot Lock Conflicts
- Troubleshoot TiFlash
- Troubleshoot Write Conflicts in Optimistic Transactions
- Troubleshoot Inconsistency Between Data and Indexes
- Performance Tuning
- Tuning Guide
- Configuration Tuning
- System Tuning
- Software Tuning
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- Tutorials
- TiDB Tools
- Overview
- Use Cases
- Download
- TiUP
- Documentation Map
- Overview
- Terminology and Concepts
- Manage TiUP Components
- FAQ
- Troubleshooting Guide
- Command Reference
- Overview
- TiUP Commands
- TiUP Cluster Commands
- Overview
- tiup cluster audit
- tiup cluster check
- tiup cluster clean
- tiup cluster deploy
- tiup cluster destroy
- tiup cluster disable
- tiup cluster display
- tiup cluster edit-config
- tiup cluster enable
- tiup cluster help
- tiup cluster import
- tiup cluster list
- tiup cluster patch
- tiup cluster prune
- tiup cluster reload
- tiup cluster rename
- tiup cluster replay
- tiup cluster restart
- tiup cluster scale-in
- tiup cluster scale-out
- tiup cluster start
- tiup cluster stop
- tiup cluster template
- tiup cluster upgrade
- TiUP DM Commands
- Overview
- tiup dm audit
- tiup dm deploy
- tiup dm destroy
- tiup dm disable
- tiup dm display
- tiup dm edit-config
- tiup dm enable
- tiup dm help
- tiup dm import
- tiup dm list
- tiup dm patch
- tiup dm prune
- tiup dm reload
- tiup dm replay
- tiup dm restart
- tiup dm scale-in
- tiup dm scale-out
- tiup dm start
- tiup dm stop
- tiup dm template
- tiup dm upgrade
- TiDB Cluster Topology Reference
- DM Cluster Topology Reference
- Mirror Reference Guide
- TiUP Components
- PingCAP Clinic Diagnostic Service
- TiDB Operator
- Dumpling
- TiDB Lightning
- TiDB Data Migration
- About TiDB Data Migration
- Architecture
- Quick Start
- Deploy a DM cluster
- Tutorials
- Advanced Tutorials
- Maintain
- Cluster Upgrade
- Tools
- Performance Tuning
- Manage Data Sources
- Manage Tasks
- Export and Import Data Sources and Task Configurations of Clusters
- Handle Alerts
- Daily Check
- Reference
- Architecture
- Command Line
- Configuration Files
- OpenAPI
- Compatibility Catalog
- Secure
- Monitoring and Alerts
- Error Codes
- Glossary
- Example
- Troubleshoot
- Release Notes
- Backup & Restore (BR)
- Point-in-Time Recovery
- TiDB Binlog
- TiCDC
- Dumpling
- sync-diff-inspector
- TiSpark
- Reference
- Cluster Architecture
- Key Monitoring Metrics
- Secure
- Privileges
- SQL
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ADMIN SHOW TELEMETRYALTER DATABASEALTER INDEXALTER INSTANCEALTER PLACEMENT POLICYALTER TABLEALTER TABLE COMPACTALTER TABLE SET TIFLASH MODEALTER USERANALYZE TABLEBACKUPBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE PLACEMENT POLICYCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP PLACEMENT POLICYDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]LOAD DATALOAD STATSMODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACERESTOREREVOKE <privileges>REVOKE <role>ROLLBACKSAVEPOINTSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [BACKUPS|RESTORES]SHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CONFIGSHOW CREATE PLACEMENT POLICYSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLACEMENTSHOW PLACEMENT FORSHOW PLACEMENT LABELSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Garbage Collection (GC)
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Placement Rules in SQL
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_CONFIGCLUSTER_HARDWARECLUSTER_INFOCLUSTER_LOADCLUSTER_LOGCLUSTER_SYSTEMINFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESINSPECTION_RESULTINSPECTION_RULESINSPECTION_SUMMARYKEY_COLUMN_USAGEMETRICS_SUMMARYMETRICS_TABLESPARTITIONSPLACEMENT_POLICIESPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVARIABLES_INFOVIEWS
METRICS_SCHEMA
- UI
- TiDB Dashboard
- Overview
- Maintain
- Access
- Overview Page
- Cluster Info Page
- Top SQL Page
- Key Visualizer Page
- Metrics Relation Graph
- SQL Statements Analysis
- Slow Queries Page
- Cluster Diagnostics
- Monitoring Page
- Search Logs Page
- Instance Profiling
- Session Management and Configuration
- FAQ
- CLI
- Command Line Flags
- Configuration File Parameters
- System Variables
- Storage Engines
- Telemetry
- Errors Codes
- Table Filter
- Schedule Replicas by Topology Labels
- FAQs
- Release Notes
- All Releases
- Release Timeline
- TiDB Versioning
- TiDB Installation Packages
- v6.2
- v6.1
- v6.0
- v5.4
- v5.3
- v5.2
- v5.1
- v5.0
- v4.0
- v3.1
- v3.0
- v2.1
- v2.0
- v1.0
- Glossary
Multiple Data Centers in One City Deployment
As a NewSQL database, TiDB combines the best features of the traditional relational database and the scalability of the NoSQL database, and is highly available across data centers (DC). This document introduces the deployment of multiple DCs in one city.
Raft protocol
Raft is a distributed consensus algorithm. Using this algorithm, both PD and TiKV, among components of the TiDB cluster, achieve disaster recovery of data, which is implemented through the following mechanisms:
- The essential role of Raft members is to perform log replication and act as a state machine. Among Raft members, data replication is implemented by replicating logs. Raft members change their own states in different conditions to elect a leader to provide services.
- Raft is a voting system that follows the majority protocol. In a Raft group, if a member gets the majority of votes, its membership changes to leader. In other words, when the majority of nodes remain in the Raft group, a leader can be elected to provide services.
To take advantage of Raft's reliability, the following conditions must be met in a real deployment scenario:
- Use at least three servers in case one server fails.
- Use at least three racks in case one rack fails.
- Use at least three DCs in case one DC fails.
- Deploy TiDB in at least three cities in case data safety issue occurs in one city.
The native Raft protocol does not have a good support for an even number of replicas. Considering the impact of cross-city network latency, three DCs in the same city might be the most suitable solution to a highly available and disaster tolerant Raft deployment.
Three DCs in one city deployment
TiDB clusters can be deployed in three DCs in the same city. In this solution, data replication across the three DCs is implemented using the Raft protocol within the cluster. These three DCs can provide read and write services at the same time. Data consistency is not affected even if one DC fails.
Simple architecture
TiDB, TiKV and PD are distributed among three DCs, which is the most common deployment with the highest availability.
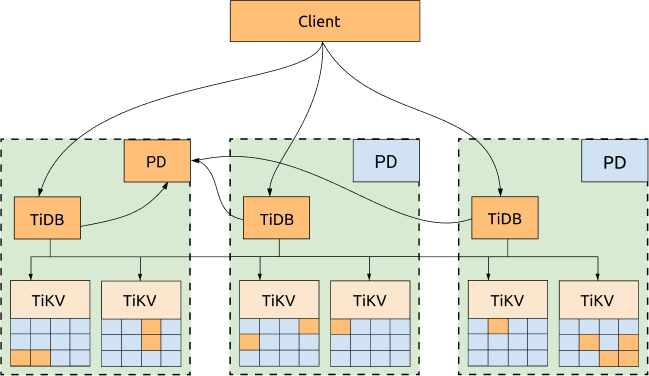
Advantages:
- All replicas are distributed among three DCs, with high availability and disaster recovery capability.
- No data will be lost if one DC is down (RPO = 0).
- Even if one DC is down, the other two DCs will automatically start leader election and automatically resume services within a reasonable amount of time (within 20 seconds in most cases). See the following diagram for more information:
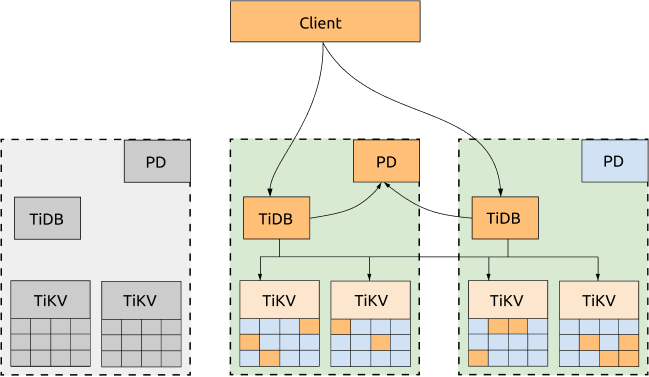
Disadvantages:
The performance can be affected by the network latency.
- For writes, all the data has to be replicated to at least 2 DCs. Because TiDB uses 2-phase commit for writes, the write latency is at least twice the latency of the network between two DCs.
- The read performance will also be affected by the network latency if the leader is not in the same DC with the TiDB node that sends the read request.
- Each TiDB transaction needs to obtain TimeStamp Oracle (TSO) from the PD leader. So if the TiDB and PD leaders are not in the same DC, the performance of the transactions will also be affected by the network latency because each transaction with the write request has to obtain TSO twice.
Optimized architecture
If not all of the three DCs need to provide services to the applications, you can dispatch all the requests to one DC and configure the scheduling policy to migrate all the TiKV Region leader and PD leader to the same DC. In this way, neither obtaining TSO nor reading TiKV Regions will be impacted by the network latency across DCs. If this DC is down, the PD leader and TiKV Region leader will be automatically elected in other surviving DCs, and you just need to switch the requests to the DCs that are still alive.
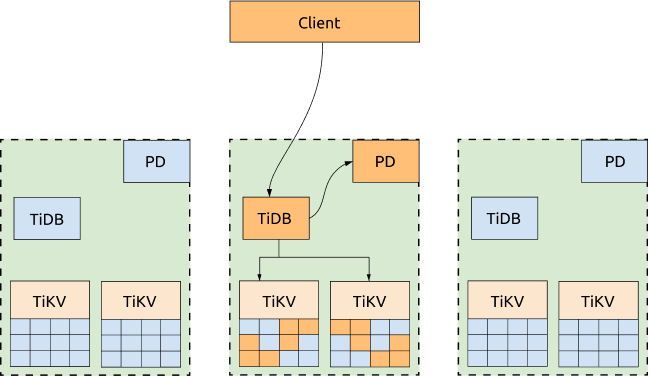
Advantages:
The cluster's read performance and the capability to get TSO are improved. A configuration template of scheduling policy is as follows:
-- Evicts all leaders of other DCs to the DC that provides services to the application.
config set label-property reject-leader LabelName labelValue
-- Migrates PD leaders and sets priority.
member leader transfer pdName1
member leader_priority pdName1 5
member leader_priority pdName2 4
member leader_priority pdName3 3
Since TiDB 5.2, the label-property configuration is not supported by default. To set the replica policy, use the placement rules.
Disadvantages:
- Write scenarios are still affected by network latency across DCs. This is because Raft follows the majority protocol and all written data must be replicated to at least two DCs.
- The TiDB server that provides services is only in one DC.
- All application traffic is processed by one DC and the performance is limited by the network bandwidth pressure of that DC.
- The capability to get TSO and the read performance are affected by whether the PD server and TiKV server are up in the DC that processes application traffic. If these servers are down, the application is still affected by the cross-center network latency.
Deployment example
This section provides a topology example, and introduces TiKV labels and TiKV labels planning.
Topology example
The following example assumes that three DCs (IDC1, IDC2, and IDC3) are located in one city; each IDC has two sets of racks and each rack has three servers. The example ignores the hybrid deployment or the scenario where multiple instances are deployed on one machine. The deployment of a TiDB cluster (three replicas) on three DCs in one city is as follows:
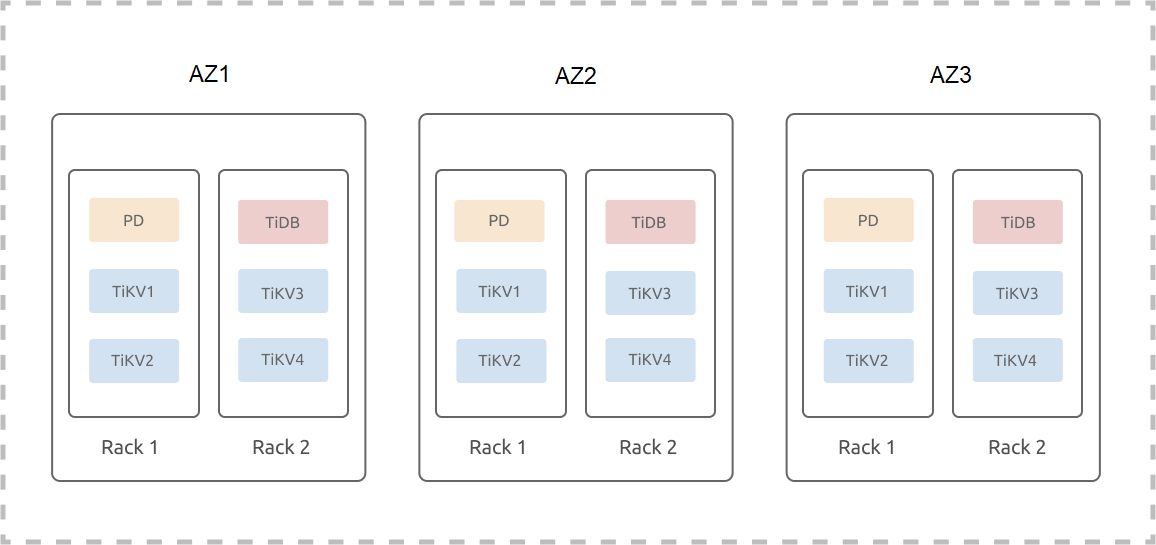
TiKV labels
TiKV is a Multi-Raft system where data is divided into Regions and the size of each Region is 96 MB by default. Three replicas of each Region form a Raft group. For a TiDB cluster of three replicas, because the number of Region replicas is independent of the TiKV instance numbers, three replicas of a Region are only scheduled to three TiKV instances. This means that even if the cluster is scaled out to have N TiKV instances, it is still a cluster of three replicas.
Because a Raft group of three replicas tolerates only one replica failure, even if the cluster is scaled out to have N TiKV instances, this cluster still tolerates only one replica failure. Two failed TiKV instances might cause some Regions to lose replicas and the data in this cluster is no longer complete. SQL requests that access data from these Regions will fail. The probability of two simultaneous failures among N TiKV instances is much higher than the probability of two simultaneous failures among three TiKV instances. This means that the more TiKV instances the Multi-Raft system is scaled out to have, the less the availability of the system.
Because of the limitation described above, label is used to describe the location information of TiKV. The label information is refreshed to the TiKV startup configuration file with deployment or rolling upgrade operations. The started TiKV reports its latest label information to PD. Based on the user-registered label name (the label metadata) and the TiKV topology, PD optimally schedules Region replicas and improves the system availability.
TiKV labels planning example
To improve the availability and disaster recovery of the system, you need to design and plan TiKV labels according to your existing physical resources and the disaster recovery capability. You also need to configure in the cluster initialization configuration file according to the planned topology:
server_configs:
pd:
replication.location-labels: ["zone","dc","rack","host"]
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { zone: "z1", dc: "d1", rack: "r1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { zone: "z1", dc: "d1", rack: "r1", host: "31" }
- host: 10.63.10.32
config:
server.labels: { zone: "z1", dc: "d1", rack: "r2", host: "32" }
- host: 10.63.10.33
config:
server.labels: { zone: "z1", dc: "d1", rack: "r2", host: "33" }
- host: 10.63.10.34
config:
server.labels: { zone: "z2", dc: "d1", rack: "r1", host: "34" }
- host: 10.63.10.35
config:
server.labels: { zone: "z2", dc: "d1", rack: "r1", host: "35" }
- host: 10.63.10.36
config:
server.labels: { zone: "z2", dc: "d1", rack: "r2", host: "36" }
- host: 10.63.10.37
config:
server.labels: { zone: "z2", dc: "d1", rack: "r2", host: "37" }
- host: 10.63.10.38
config:
server.labels: { zone: "z3", dc: "d1", rack: "r1", host: "38" }
- host: 10.63.10.39
config:
server.labels: { zone: "z3", dc: "d1", rack: "r1", host: "39" }
- host: 10.63.10.40
config:
server.labels: { zone: "z3", dc: "d1", rack: "r2", host: "40" }
- host: 10.63.10.41
config:
server.labels: { zone: "z3", dc: "d1", rack: "r2", host: "41" }
In the example above, zone is the logical availability zone layer that controls the isolation of replicas (three replicas in the example cluster).
Considering that the DC might be scaled out in the future, the three-layer label structure (dc, rack, host) is not directly adopted. Assuming that d2, d3, and d4 are to be scaled out, you only need to scale out the DCs in the corresponding availability zone and scale out the racks in the corresponding DC.
If this three-layer label structure is directly adopted, after scaling out a DC, you might need to apply new labels and the data in TiKV needs to be rebalanced.
High availability and disaster recovery analysis
The multiple DCs in one city deployment can guarantee that if one DC fails, the cluster can automatically recover services without manual intervention. Data consistency is also guaranteed. Note that scheduling policies are used to optimize performance, but when failure occurs, these policies prioritize availability over performance.