- Docs Home
- About TiDB
- Quick Start
- Develop
- Overview
- Quick Start
- Build a TiDB Cluster in TiDB Cloud (Developer Tier)
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Third-party Support
- Deploy
- Software and Hardware Requirements
- Environment Configuration Checklist
- Plan Cluster Topology
- Install and Start
- Verify Cluster Status
- Test Cluster Performance
- Migrate
- Overview
- Migration Tools
- Migration Scenarios
- Migrate from Aurora
- Migrate MySQL of Small Datasets
- Migrate MySQL of Large Datasets
- Migrate and Merge MySQL Shards of Small Datasets
- Migrate and Merge MySQL Shards of Large Datasets
- Migrate from CSV Files
- Migrate from SQL Files
- Migrate from One TiDB Cluster to Another TiDB Cluster
- Migrate from TiDB to MySQL-compatible Databases
- Advanced Migration
- Integrate
- Overview
- Integration Scenarios
- Maintain
- Monitor and Alert
- Troubleshoot
- TiDB Troubleshooting Map
- Identify Slow Queries
- Analyze Slow Queries
- SQL Diagnostics
- Identify Expensive Queries Using Top SQL
- Identify Expensive Queries Using Logs
- Statement Summary Tables
- Troubleshoot Hotspot Issues
- Troubleshoot Increased Read and Write Latency
- Save and Restore the On-Site Information of a Cluster
- Troubleshoot Cluster Setup
- Troubleshoot High Disk I/O Usage
- Troubleshoot Lock Conflicts
- Troubleshoot TiFlash
- Troubleshoot Write Conflicts in Optimistic Transactions
- Troubleshoot Inconsistency Between Data and Indexes
- Performance Tuning
- Tuning Guide
- Configuration Tuning
- System Tuning
- Software Tuning
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- Tutorials
- TiDB Tools
- Overview
- Use Cases
- Download
- TiUP
- Documentation Map
- Overview
- Terminology and Concepts
- Manage TiUP Components
- FAQ
- Troubleshooting Guide
- Command Reference
- Overview
- TiUP Commands
- TiUP Cluster Commands
- Overview
- tiup cluster audit
- tiup cluster check
- tiup cluster clean
- tiup cluster deploy
- tiup cluster destroy
- tiup cluster disable
- tiup cluster display
- tiup cluster edit-config
- tiup cluster enable
- tiup cluster help
- tiup cluster import
- tiup cluster list
- tiup cluster patch
- tiup cluster prune
- tiup cluster reload
- tiup cluster rename
- tiup cluster replay
- tiup cluster restart
- tiup cluster scale-in
- tiup cluster scale-out
- tiup cluster start
- tiup cluster stop
- tiup cluster template
- tiup cluster upgrade
- TiUP DM Commands
- Overview
- tiup dm audit
- tiup dm deploy
- tiup dm destroy
- tiup dm disable
- tiup dm display
- tiup dm edit-config
- tiup dm enable
- tiup dm help
- tiup dm import
- tiup dm list
- tiup dm patch
- tiup dm prune
- tiup dm reload
- tiup dm replay
- tiup dm restart
- tiup dm scale-in
- tiup dm scale-out
- tiup dm start
- tiup dm stop
- tiup dm template
- tiup dm upgrade
- TiDB Cluster Topology Reference
- DM Cluster Topology Reference
- Mirror Reference Guide
- TiUP Components
- PingCAP Clinic Diagnostic Service
- TiDB Operator
- Dumpling
- TiDB Lightning
- TiDB Data Migration
- About TiDB Data Migration
- Architecture
- Quick Start
- Deploy a DM cluster
- Tutorials
- Advanced Tutorials
- Maintain
- Cluster Upgrade
- Tools
- Performance Tuning
- Manage Data Sources
- Manage Tasks
- Export and Import Data Sources and Task Configurations of Clusters
- Handle Alerts
- Daily Check
- Reference
- Architecture
- Command Line
- Configuration Files
- OpenAPI
- Compatibility Catalog
- Secure
- Monitoring and Alerts
- Error Codes
- Glossary
- Example
- Troubleshoot
- Release Notes
- Backup & Restore (BR)
- Point-in-Time Recovery
- TiDB Binlog
- TiCDC
- Dumpling
- sync-diff-inspector
- TiSpark
- Reference
- Cluster Architecture
- Key Monitoring Metrics
- Secure
- Privileges
- SQL
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ADMIN SHOW TELEMETRYALTER DATABASEALTER INDEXALTER INSTANCEALTER PLACEMENT POLICYALTER TABLEALTER TABLE COMPACTALTER TABLE SET TIFLASH MODEALTER USERANALYZE TABLEBACKUPBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE PLACEMENT POLICYCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP PLACEMENT POLICYDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]LOAD DATALOAD STATSMODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACERESTOREREVOKE <privileges>REVOKE <role>ROLLBACKSAVEPOINTSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [BACKUPS|RESTORES]SHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CONFIGSHOW CREATE PLACEMENT POLICYSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLACEMENTSHOW PLACEMENT FORSHOW PLACEMENT LABELSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Garbage Collection (GC)
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Placement Rules in SQL
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_CONFIGCLUSTER_HARDWARECLUSTER_INFOCLUSTER_LOADCLUSTER_LOGCLUSTER_SYSTEMINFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESINSPECTION_RESULTINSPECTION_RULESINSPECTION_SUMMARYKEY_COLUMN_USAGEMETRICS_SUMMARYMETRICS_TABLESPARTITIONSPLACEMENT_POLICIESPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVARIABLES_INFOVIEWS
METRICS_SCHEMA
- UI
- TiDB Dashboard
- Overview
- Maintain
- Access
- Overview Page
- Cluster Info Page
- Top SQL Page
- Key Visualizer Page
- Metrics Relation Graph
- SQL Statements Analysis
- Slow Queries Page
- Cluster Diagnostics
- Monitoring Page
- Search Logs Page
- Instance Profiling
- Session Management and Configuration
- FAQ
- CLI
- Command Line Flags
- Configuration File Parameters
- System Variables
- Storage Engines
- Telemetry
- Errors Codes
- Table Filter
- Schedule Replicas by Topology Labels
- FAQs
- Release Notes
- All Releases
- Release Timeline
- TiDB Versioning
- TiDB Installation Packages
- v6.2
- v6.1
- v6.0
- v5.4
- v5.3
- v5.2
- v5.1
- v5.0
- v4.0
- v3.1
- v3.0
- v2.1
- v2.0
- v1.0
- Glossary
Transaction Restraints
This document briefly introduces the transaction restraints in TiDB.
Isolation levels
The isolation levels supported by TiDB are RC (Read Committed) and SI (Snapshot Isolation), where SI is basically equivalent to the RR (Repeatable Read) isolation level.
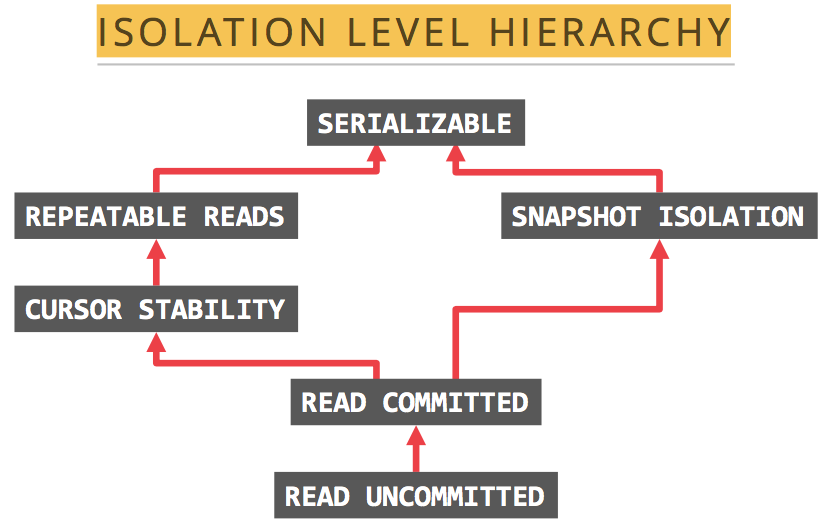
Snapshot Isolation can avoid phantom reads
The SI isolation level of TiDB can avoid Phantom Reads, but the RR in ANSI/ISO SQL standard cannot.
The following two examples show what phantom reads is.
Example 1: Transaction A first gets
nrows according to the query, and then Transaction B changesmrows other than thesenrows or addsmrows that match the query of Transaction A. When Transaction A runs the query again, it finds that there aren+mrows that match the condition. It is like a phantom, so it is called a phantom read.Example 2: Admin A changes the grades of all students in the database from specific scores to ABCDE grades, but Admin B inserts a record with a specific score at this time. When Admin A finishes changing and finds that there is still a record (the one inserted by Admin B) that has not been changed yet. That is a phantom read.
SI cannot avoid write skew
TiDB's SI isolation level cannot avoid write skew exceptions. You can use the SELECT FOR UPDATE syntax to avoid write skew exceptions.
A write skew exception occurs when two concurrent transactions read different but related records, and then each transaction updates the data it reads and eventually commits the transaction. If there is a constraint between these related records that cannot be modified concurrently by multiple transactions, then the end result will violate the constraint.
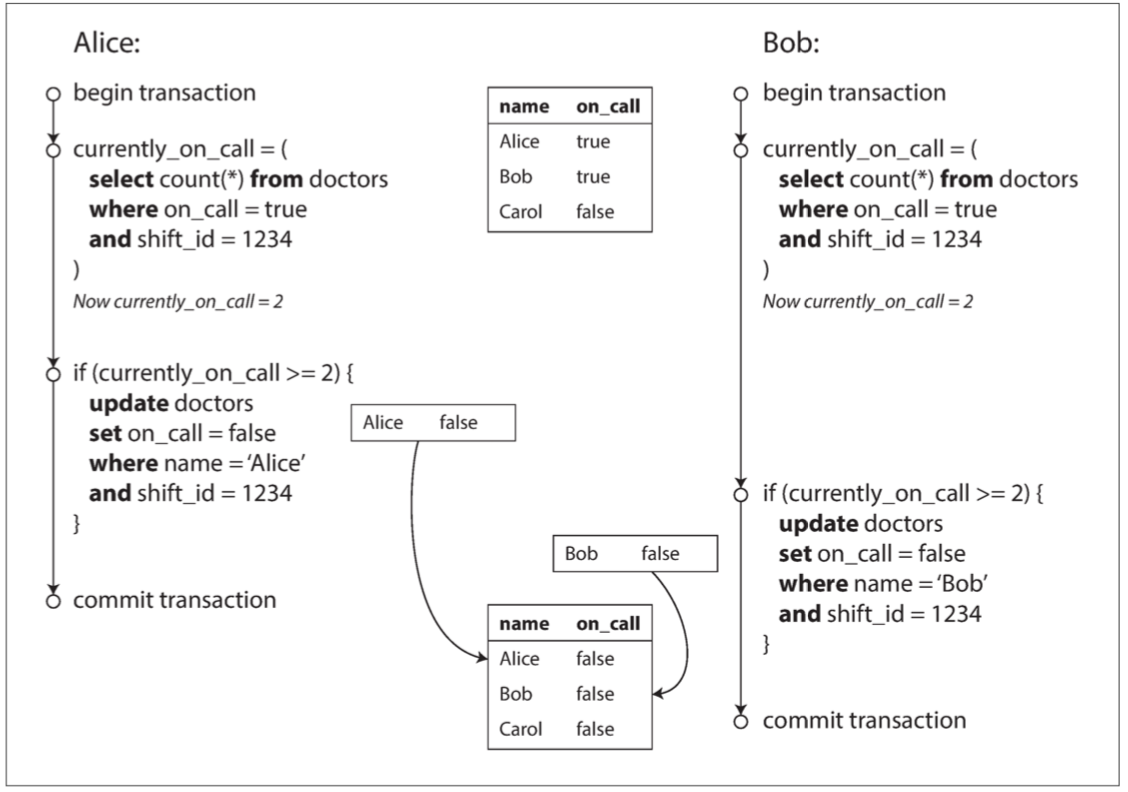
For example, suppose you are writing a doctor shift management program for a hospital. Hospitals typically require several doctors to be on call at the same time, but the minimum requirement is that at least one doctor is on call. Doctors can drop their shifts (for example, if they are feeling sick) as long as at least one doctor is on call during that shift.
Now there is a situation where doctors Alice and Bob are on call. Both are feeling sick, so they decide to take sick leave. They happen to click the button at the same time. Let's simulate this process with the following program:
- Java
- Golang
package com.pingcap.txn.write.skew;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class EffectWriteSkew {
public static void main(String[] args) throws SQLException, InterruptedException {
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:4000/test?useServerPrepStmts=true&cachePrepStmts=true");
ds.setUsername("root");
// prepare data
Connection connection = ds.getConnection();
createDoctorTable(connection);
createDoctor(connection, 1, "Alice", true, 123);
createDoctor(connection, 2, "Bob", true, 123);
createDoctor(connection, 3, "Carol", false, 123);
Semaphore txn1Pass = new Semaphore(0);
CountDownLatch countDownLatch = new CountDownLatch(2);
ExecutorService threadPool = Executors.newFixedThreadPool(2);
threadPool.execute(() -> {
askForLeave(ds, txn1Pass, 1, 1);
countDownLatch.countDown();
});
threadPool.execute(() -> {
askForLeave(ds, txn1Pass, 2, 2);
countDownLatch.countDown();
});
countDownLatch.await();
}
public static void createDoctorTable(Connection connection) throws SQLException {
connection.createStatement().executeUpdate("CREATE TABLE `doctors` (" +
" `id` int(11) NOT NULL," +
" `name` varchar(255) DEFAULT NULL," +
" `on_call` tinyint(1) DEFAULT NULL," +
" `shift_id` int(11) DEFAULT NULL," +
" PRIMARY KEY (`id`)," +
" KEY `idx_shift_id` (`shift_id`)" +
" ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin");
}
public static void createDoctor(Connection connection, Integer id, String name, Boolean onCall, Integer shiftID) throws SQLException {
PreparedStatement insert = connection.prepareStatement(
"INSERT INTO `doctors` (`id`, `name`, `on_call`, `shift_id`) VALUES (?, ?, ?, ?)");
insert.setInt(1, id);
insert.setString(2, name);
insert.setBoolean(3, onCall);
insert.setInt(4, shiftID);
insert.executeUpdate();
}
public static void askForLeave(HikariDataSource ds, Semaphore txn1Pass, Integer txnID, Integer doctorID) {
try(Connection connection = ds.getConnection()) {
try {
connection.setAutoCommit(false);
String comment = txnID == 2 ? " " : "" + "/* txn #{txn_id} */ ";
connection.createStatement().executeUpdate(comment + "BEGIN");
// Txn 1 should be waiting for txn 2 done
if (txnID == 1) {
txn1Pass.acquire();
}
PreparedStatement currentOnCallQuery = connection.prepareStatement(comment +
"SELECT COUNT(*) AS `count` FROM `doctors` WHERE `on_call` = ? AND `shift_id` = ?");
currentOnCallQuery.setBoolean(1, true);
currentOnCallQuery.setInt(2, 123);
ResultSet res = currentOnCallQuery.executeQuery();
if (!res.next()) {
throw new RuntimeException("error query");
} else {
int count = res.getInt("count");
if (count >= 2) {
// If current on-call doctor has 2 or more, this doctor can leave
PreparedStatement insert = connection.prepareStatement( comment +
"UPDATE `doctors` SET `on_call` = ? WHERE `id` = ? AND `shift_id` = ?");
insert.setBoolean(1, false);
insert.setInt(2, doctorID);
insert.setInt(3, 123);
insert.executeUpdate();
connection.commit();
} else {
throw new RuntimeException("At least one doctor is on call");
}
}
// Txn 2 done, let txn 1 run again
if (txnID == 2) {
txn1Pass.release();
}
} catch (Exception e) {
// If got any error, you should roll back, data is priceless
connection.rollback();
e.printStackTrace();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
To adapt TiDB transactions, write a util according to the following code:
package main
import (
"database/sql"
"fmt"
"sync"
"github.com/pingcap-inc/tidb-example-golang/util"
_ "github.com/go-sql-driver/mysql"
)
func main() {
openDB("mysql", "root:@tcp(127.0.0.1:4000)/test", func(db *sql.DB) {
writeSkew(db)
})
}
func openDB(driverName, dataSourceName string, runnable func(db *sql.DB)) {
db, err := sql.Open(driverName, dataSourceName)
if err != nil {
panic(err)
}
defer db.Close()
runnable(db)
}
func writeSkew(db *sql.DB) {
err := prepareData(db)
if err != nil {
panic(err)
}
waitingChan, waitGroup := make(chan bool), sync.WaitGroup{}
waitGroup.Add(1)
go func() {
defer waitGroup.Done()
err = askForLeave(db, waitingChan, 1, 1)
if err != nil {
panic(err)
}
}()
waitGroup.Add(1)
go func() {
defer waitGroup.Done()
err = askForLeave(db, waitingChan, 2, 2)
if err != nil {
panic(err)
}
}()
waitGroup.Wait()
}
func askForLeave(db *sql.DB, waitingChan chan bool, goroutineID, doctorID int) error {
txnComment := fmt.Sprintf("/* txn %d */ ", goroutineID)
if goroutineID != 1 {
txnComment = "\t" + txnComment
}
txn, err := util.TiDBSqlBegin(db, true)
if err != nil {
return err
}
fmt.Println(txnComment + "start txn")
// Txn 1 should be waiting until txn 2 is done.
if goroutineID == 1 {
<-waitingChan
}
txnFunc := func() error {
queryCurrentOnCall := "SELECT COUNT(*) AS `count` FROM `doctors` WHERE `on_call` = ? AND `shift_id` = ?"
rows, err := txn.Query(queryCurrentOnCall, true, 123)
if err != nil {
return err
}
defer rows.Close()
fmt.Println(txnComment + queryCurrentOnCall + " successful")
count := 0
if rows.Next() {
err = rows.Scan(&count)
if err != nil {
return err
}
}
rows.Close()
if count < 2 {
return fmt.Errorf("at least one doctor is on call")
}
shift := "UPDATE `doctors` SET `on_call` = ? WHERE `id` = ? AND `shift_id` = ?"
_, err = txn.Exec(shift, false, doctorID, 123)
if err == nil {
fmt.Println(txnComment + shift + " successful")
}
return err
}
err = txnFunc()
if err == nil {
txn.Commit()
fmt.Println("[runTxn] commit success")
} else {
txn.Rollback()
fmt.Printf("[runTxn] got an error, rollback: %+v\n", err)
}
// Txn 2 is done. Let txn 1 run again.
if goroutineID == 2 {
waitingChan <- true
}
return nil
}
func prepareData(db *sql.DB) error {
err := createDoctorTable(db)
if err != nil {
return err
}
err = createDoctor(db, 1, "Alice", true, 123)
if err != nil {
return err
}
err = createDoctor(db, 2, "Bob", true, 123)
if err != nil {
return err
}
err = createDoctor(db, 3, "Carol", false, 123)
if err != nil {
return err
}
return nil
}
func createDoctorTable(db *sql.DB) error {
_, err := db.Exec("CREATE TABLE IF NOT EXISTS `doctors` (" +
" `id` int(11) NOT NULL," +
" `name` varchar(255) DEFAULT NULL," +
" `on_call` tinyint(1) DEFAULT NULL," +
" `shift_id` int(11) DEFAULT NULL," +
" PRIMARY KEY (`id`)," +
" KEY `idx_shift_id` (`shift_id`)" +
" ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin")
return err
}
func createDoctor(db *sql.DB, id int, name string, onCall bool, shiftID int) error {
_, err := db.Exec("INSERT INTO `doctors` (`id`, `name`, `on_call`, `shift_id`) VALUES (?, ?, ?, ?)",
id, name, onCall, shiftID)
return err
}
SQL log:
/* txn 1 */ BEGIN
/* txn 2 */ BEGIN
/* txn 2 */ SELECT COUNT(*) as `count` FROM `doctors` WHERE `on_call` = 1 AND `shift_id` = 123
/* txn 2 */ UPDATE `doctors` SET `on_call` = 0 WHERE `id` = 2 AND `shift_id` = 123
/* txn 2 */ COMMIT
/* txn 1 */ SELECT COUNT(*) AS `count` FROM `doctors` WHERE `on_call` = 1 and `shift_id` = 123
/* txn 1 */ UPDATE `doctors` SET `on_call` = 0 WHERE `id` = 1 AND `shift_id` = 123
/* txn 1 */ COMMIT
Running result:
mysql> SELECT * FROM doctors;
+----+-------+---------+----------+
| id | name | on_call | shift_id |
+----+-------+---------+----------+
| 1 | Alice | 0 | 123 |
| 2 | Bob | 0 | 123 |
| 3 | Carol | 0 | 123 |
+----+-------+---------+----------+
In both transactions, the application first checks if two or more doctors are on call; if so, it assumes that one doctor can safely take leave. Since the database uses the snapshot isolation, both checks return 2, so both transactions move on to the next stage. Alice updates her record to be off duty, and so does Bob. Both transactions are successfully committed. Now there are no doctors on duty which violates the requirement that at least one doctor should be on call. The following diagram (quoted from Designing Data-Intensive Applications) illustrates what actually happens.
Now let's change the sample program to use SELECT FOR UPDATE to avoid the write skew problem:
- Java
- Golang
package com.pingcap.txn.write.skew;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class EffectWriteSkew {
public static void main(String[] args) throws SQLException, InterruptedException {
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:4000/test?useServerPrepStmts=true&cachePrepStmts=true");
ds.setUsername("root");
// prepare data
Connection connection = ds.getConnection();
createDoctorTable(connection);
createDoctor(connection, 1, "Alice", true, 123);
createDoctor(connection, 2, "Bob", true, 123);
createDoctor(connection, 3, "Carol", false, 123);
Semaphore txn1Pass = new Semaphore(0);
CountDownLatch countDownLatch = new CountDownLatch(2);
ExecutorService threadPool = Executors.newFixedThreadPool(2);
threadPool.execute(() -> {
askForLeave(ds, txn1Pass, 1, 1);
countDownLatch.countDown();
});
threadPool.execute(() -> {
askForLeave(ds, txn1Pass, 2, 2);
countDownLatch.countDown();
});
countDownLatch.await();
}
public static void createDoctorTable(Connection connection) throws SQLException {
connection.createStatement().executeUpdate("CREATE TABLE `doctors` (" +
" `id` int(11) NOT NULL," +
" `name` varchar(255) DEFAULT NULL," +
" `on_call` tinyint(1) DEFAULT NULL," +
" `shift_id` int(11) DEFAULT NULL," +
" PRIMARY KEY (`id`)," +
" KEY `idx_shift_id` (`shift_id`)" +
" ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin");
}
public static void createDoctor(Connection connection, Integer id, String name, Boolean onCall, Integer shiftID) throws SQLException {
PreparedStatement insert = connection.prepareStatement(
"INSERT INTO `doctors` (`id`, `name`, `on_call`, `shift_id`) VALUES (?, ?, ?, ?)");
insert.setInt(1, id);
insert.setString(2, name);
insert.setBoolean(3, onCall);
insert.setInt(4, shiftID);
insert.executeUpdate();
}
public static void askForLeave(HikariDataSource ds, Semaphore txn1Pass, Integer txnID, Integer doctorID) {
try(Connection connection = ds.getConnection()) {
try {
connection.setAutoCommit(false);
String comment = txnID == 2 ? " " : "" + "/* txn #{txn_id} */ ";
connection.createStatement().executeUpdate(comment + "BEGIN");
// Txn 1 should be waiting for txn 2 done
if (txnID == 1) {
txn1Pass.acquire();
}
PreparedStatement currentOnCallQuery = connection.prepareStatement(comment +
"SELECT COUNT(*) AS `count` FROM `doctors` WHERE `on_call` = ? AND `shift_id` = ? FOR UPDATE");
currentOnCallQuery.setBoolean(1, true);
currentOnCallQuery.setInt(2, 123);
ResultSet res = currentOnCallQuery.executeQuery();
if (!res.next()) {
throw new RuntimeException("error query");
} else {
int count = res.getInt("count");
if (count >= 2) {
// If current on-call doctor has 2 or more, this doctor can leave
PreparedStatement insert = connection.prepareStatement( comment +
"UPDATE `doctors` SET `on_call` = ? WHERE `id` = ? AND `shift_id` = ?");
insert.setBoolean(1, false);
insert.setInt(2, doctorID);
insert.setInt(3, 123);
insert.executeUpdate();
connection.commit();
} else {
throw new RuntimeException("At least one doctor is on call");
}
}
// Txn 2 done, let txn 1 run again
if (txnID == 2) {
txn1Pass.release();
}
} catch (Exception e) {
// If got any error, you should roll back, data is priceless
connection.rollback();
e.printStackTrace();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
package main
import (
"database/sql"
"fmt"
"sync"
"github.com/pingcap-inc/tidb-example-golang/util"
_ "github.com/go-sql-driver/mysql"
)
func main() {
openDB("mysql", "root:@tcp(127.0.0.1:4000)/test", func(db *sql.DB) {
writeSkew(db)
})
}
func openDB(driverName, dataSourceName string, runnable func(db *sql.DB)) {
db, err := sql.Open(driverName, dataSourceName)
if err != nil {
panic(err)
}
defer db.Close()
runnable(db)
}
func writeSkew(db *sql.DB) {
err := prepareData(db)
if err != nil {
panic(err)
}
waitingChan, waitGroup := make(chan bool), sync.WaitGroup{}
waitGroup.Add(1)
go func() {
defer waitGroup.Done()
err = askForLeave(db, waitingChan, 1, 1)
if err != nil {
panic(err)
}
}()
waitGroup.Add(1)
go func() {
defer waitGroup.Done()
err = askForLeave(db, waitingChan, 2, 2)
if err != nil {
panic(err)
}
}()
waitGroup.Wait()
}
func askForLeave(db *sql.DB, waitingChan chan bool, goroutineID, doctorID int) error {
txnComment := fmt.Sprintf("/* txn %d */ ", goroutineID)
if goroutineID != 1 {
txnComment = "\t" + txnComment
}
txn, err := util.TiDBSqlBegin(db, true)
if err != nil {
return err
}
fmt.Println(txnComment + "start txn")
// Txn 1 should be waiting until txn 2 is done.
if goroutineID == 1 {
<-waitingChan
}
txnFunc := func() error {
queryCurrentOnCall := "SELECT COUNT(*) AS `count` FROM `doctors` WHERE `on_call` = ? AND `shift_id` = ?"
rows, err := txn.Query(queryCurrentOnCall, true, 123)
if err != nil {
return err
}
defer rows.Close()
fmt.Println(txnComment + queryCurrentOnCall + " successful")
count := 0
if rows.Next() {
err = rows.Scan(&count)
if err != nil {
return err
}
}
rows.Close()
if count < 2 {
return fmt.Errorf("at least one doctor is on call")
}
shift := "UPDATE `doctors` SET `on_call` = ? WHERE `id` = ? AND `shift_id` = ?"
_, err = txn.Exec(shift, false, doctorID, 123)
if err == nil {
fmt.Println(txnComment + shift + " successful")
}
return err
}
err = txnFunc()
if err == nil {
txn.Commit()
fmt.Println("[runTxn] commit success")
} else {
txn.Rollback()
fmt.Printf("[runTxn] got an error, rollback: %+v\n", err)
}
// Txn 2 is done. Let txn 1 run again.
if goroutineID == 2 {
waitingChan <- true
}
return nil
}
func prepareData(db *sql.DB) error {
err := createDoctorTable(db)
if err != nil {
return err
}
err = createDoctor(db, 1, "Alice", true, 123)
if err != nil {
return err
}
err = createDoctor(db, 2, "Bob", true, 123)
if err != nil {
return err
}
err = createDoctor(db, 3, "Carol", false, 123)
if err != nil {
return err
}
return nil
}
func createDoctorTable(db *sql.DB) error {
_, err := db.Exec("CREATE TABLE IF NOT EXISTS `doctors` (" +
" `id` int(11) NOT NULL," +
" `name` varchar(255) DEFAULT NULL," +
" `on_call` tinyint(1) DEFAULT NULL," +
" `shift_id` int(11) DEFAULT NULL," +
" PRIMARY KEY (`id`)," +
" KEY `idx_shift_id` (`shift_id`)" +
" ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin")
return err
}
func createDoctor(db *sql.DB, id int, name string, onCall bool, shiftID int) error {
_, err := db.Exec("INSERT INTO `doctors` (`id`, `name`, `on_call`, `shift_id`) VALUES (?, ?, ?, ?)",
id, name, onCall, shiftID)
return err
}
SQL log:
/* txn 1 */ BEGIN
/* txn 2 */ BEGIN
/* txn 2 */ SELECT COUNT(*) AS `count` FROM `doctors` WHERE on_call = 1 AND `shift_id` = 123 FOR UPDATE
/* txn 2 */ UPDATE `doctors` SET on_call = 0 WHERE `id` = 2 AND `shift_id` = 123
/* txn 2 */ COMMIT
/* txn 1 */ SELECT COUNT(*) AS `count` FROM `doctors` WHERE `on_call` = 1 FOR UPDATE
At least one doctor is on call
/* txn 1 */ ROLLBACK
Running result:
mysql> SELECT * FROM doctors;
+----+-------+---------+----------+
| id | name | on_call | shift_id |
+----+-------+---------+----------+
| 1 | Alice | 1 | 123 |
| 2 | Bob | 0 | 123 |
| 3 | Carol | 0 | 123 |
+----+-------+---------+----------+
Support for savepoint and nested transactions
The PROPAGATION_NESTED propagation behavior supported by Spring triggers a nested transaction, which is a child transaction that is started independently of the current transaction. A savepoint is recorded when the nested transaction starts. If the nested transaction fails, the transaction will roll back to the savepoint state. The nested transaction is part of the outer transaction and will be committed together with the outer transaction.
The following example demonstrates the savepoint mechanism:
mysql> BEGIN;
mysql> INSERT INTO T2 VALUES(100);
mysql> SAVEPOINT svp1;
mysql> INSERT INTO T2 VALUES(200);
mysql> ROLLBACK TO SAVEPOINT svp1;
mysql> RELEASE SAVEPOINT svp1;
mysql> COMMIT;
mysql> SELECT * FROM T2;
+------+
| ID |
+------+
| 100 |
+------+
Since v6.2.0, TiDB supports the savepoint feature. If your TiDB cluster is earlier than v6.2.0, your TiDB cluster does not support the PROPAGATION_NESTED behavior. If your applications are based on the Java Spring framework that use the PROPAGATION_NESTED propagation behavior, you need to adapt it on the application side to remove the logic for nested transactions.
Large transaction restrictions
The basic principle is to limit the size of the transaction. At the KV level, TiDB has a restriction on the size of a single transaction. At the SQL level, one row of data is mapped to one KV entry, and each additional index will add one KV entry. The restriction is as follows at the SQL level:
- The maximum single row record size is
120 MB. You can configure it byperformance.txn-entry-size-limitfor TiDB v5.0 and later versions. The value is6 MBfor earlier versions. - The maximum single transaction size supported is
10 GB. You can configure it byperformance.txn-total-size-limitfor TiDB v4.0 and later versions. The value is100 MBfor earlier versions.
Note that for both the size restrictions and row restrictions, you should also consider the overhead of encoding and additional keys for the transaction during the transaction execution. To achieve optimal performance, it is recommended to write one transaction every 100 ~ 500 rows.
Auto-committed SELECT FOR UPDATE statements do NOT wait for locks
Currently locks are not added to auto-committed SELECT FOR UPDATE statements. The effect is shown in the following figure:
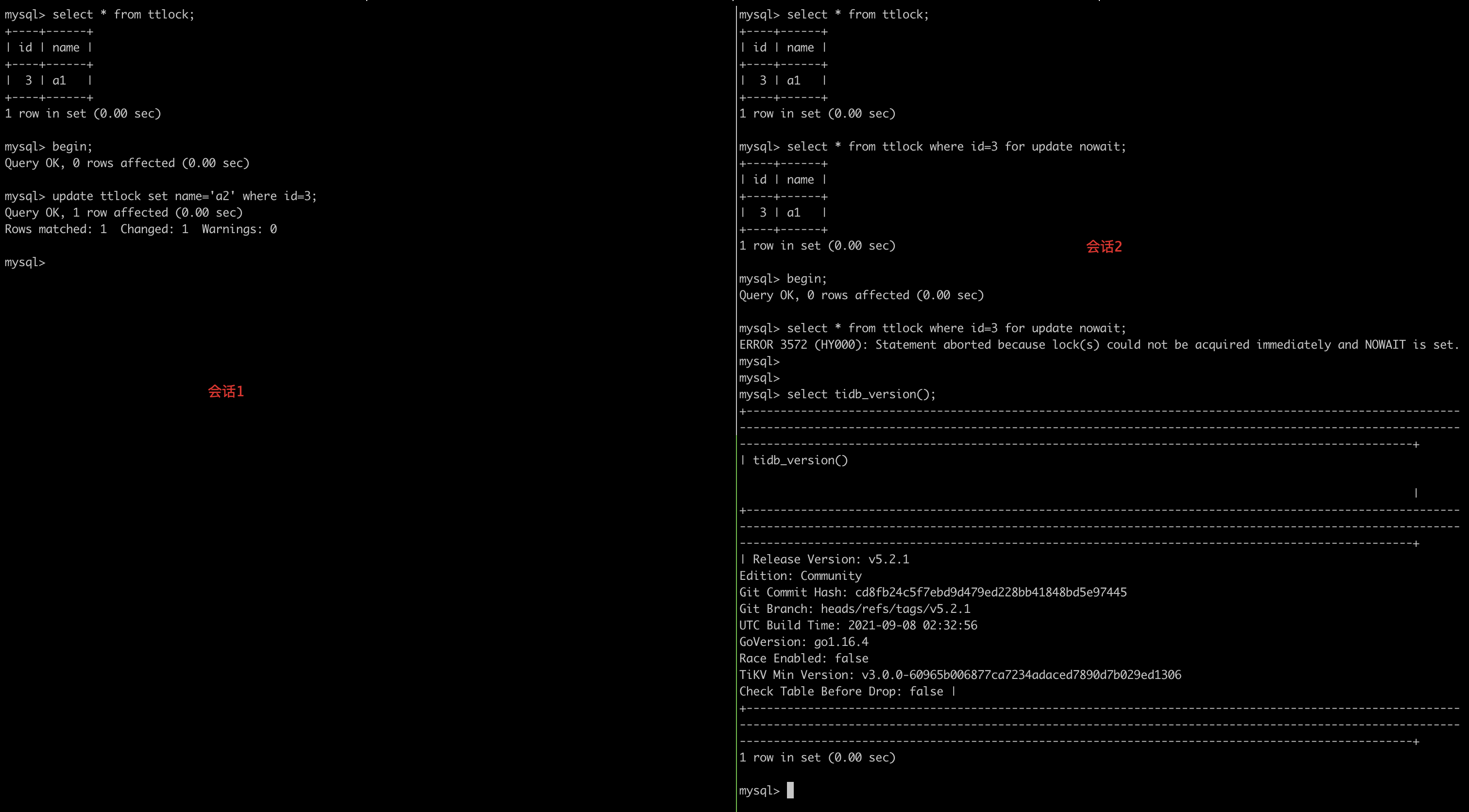
This is a known incompatibility issue with MySQL. You can solve this issue by using the explicit BEGIN;COMMIT; statements.