- Docs Home
- About TiDB Cloud
- Get Started
- Develop Applications
- Overview
- Quick Start
- Build a TiDB Developer Cluster
- CRUD SQL in TiDB
- Build a Simple CRUD App with TiDB
- Example Applications
- Connect to TiDB
- Design Database Schema
- Write Data
- Read Data
- Transaction
- Optimize
- Troubleshoot
- Reference
- Cloud Native Development Environment
- Manage Cluster
- Plan Your Cluster
- Create a TiDB Cluster
- Connect to Your TiDB Cluster
- Set Up VPC Peering Connections
- Use an HTAP Cluster with TiFlash
- Scale a TiDB Cluster
- Upgrade a TiDB Cluster
- Delete a TiDB Cluster
- Use TiDB Cloud API (Beta)
- Migrate Data
- Import Sample Data
- Migrate Data into TiDB
- Configure Amazon S3 Access and GCS Access
- Migrate from MySQL-Compatible Databases
- Migrate Incremental Data from MySQL-Compatible Databases
- Migrate from Amazon Aurora MySQL in Bulk
- Import or Migrate from Amazon S3 or GCS to TiDB Cloud
- Import CSV Files from Amazon S3 or GCS into TiDB Cloud
- Import Apache Parquet Files from Amazon S3 or GCS into TiDB Cloud
- Troubleshoot Access Denied Errors during Data Import from Amazon S3
- Export Data from TiDB
- Back Up and Restore
- Monitor and Alert
- Overview
- Built-in Monitoring
- Built-in Alerting
- Third-Party Monitoring Integrations
- Tune Performance
- Overview
- Analyze Performance
- SQL Tuning
- Overview
- Understanding the Query Execution Plan
- SQL Optimization Process
- Overview
- Logic Optimization
- Physical Optimization
- Prepare Execution Plan Cache
- Control Execution Plans
- TiKV Follower Read
- Coprocessor Cache
- Garbage Collection (GC)
- Tune TiFlash performance
- Manage User Access
- Billing
- Reference
- TiDB Cluster Architecture
- TiDB Cloud Cluster Limits and Quotas
- TiDB Limitations
- SQL
- Explore SQL with TiDB
- SQL Language Structure and Syntax
- SQL Statements
ADD COLUMNADD INDEXADMINADMIN CANCEL DDLADMIN CHECKSUM TABLEADMIN CHECK [TABLE|INDEX]ADMIN SHOW DDL [JOBS|QUERIES]ALTER DATABASEALTER INDEXALTER TABLEALTER TABLE COMPACTALTER USERANALYZE TABLEBATCHBEGINCHANGE COLUMNCOMMITCHANGE DRAINERCHANGE PUMPCREATE [GLOBAL|SESSION] BINDINGCREATE DATABASECREATE INDEXCREATE ROLECREATE SEQUENCECREATE TABLE LIKECREATE TABLECREATE USERCREATE VIEWDEALLOCATEDELETEDESCDESCRIBEDODROP [GLOBAL|SESSION] BINDINGDROP COLUMNDROP DATABASEDROP INDEXDROP ROLEDROP SEQUENCEDROP STATSDROP TABLEDROP USERDROP VIEWEXECUTEEXPLAIN ANALYZEEXPLAINFLASHBACK TABLEFLUSH PRIVILEGESFLUSH STATUSFLUSH TABLESGRANT <privileges>GRANT <role>INSERTKILL [TIDB]MODIFY COLUMNPREPARERECOVER TABLERENAME INDEXRENAME TABLEREPLACEREVOKE <privileges>REVOKE <role>ROLLBACKSELECTSET DEFAULT ROLESET [NAMES|CHARACTER SET]SET PASSWORDSET ROLESET TRANSACTIONSET [GLOBAL|SESSION] <variable>SHOW ANALYZE STATUSSHOW [GLOBAL|SESSION] BINDINGSSHOW BUILTINSSHOW CHARACTER SETSHOW COLLATIONSHOW [FULL] COLUMNS FROMSHOW CREATE SEQUENCESHOW CREATE TABLESHOW CREATE USERSHOW DATABASESSHOW DRAINER STATUSSHOW ENGINESSHOW ERRORSSHOW [FULL] FIELDS FROMSHOW GRANTSSHOW INDEX [FROM|IN]SHOW INDEXES [FROM|IN]SHOW KEYS [FROM|IN]SHOW MASTER STATUSSHOW PLUGINSSHOW PRIVILEGESSHOW [FULL] PROCESSSLISTSHOW PROFILESSHOW PUMP STATUSSHOW SCHEMASSHOW STATS_HEALTHYSHOW STATS_HISTOGRAMSSHOW STATS_METASHOW STATUSSHOW TABLE NEXT_ROW_IDSHOW TABLE REGIONSSHOW TABLE STATUSSHOW [FULL] TABLESSHOW [GLOBAL|SESSION] VARIABLESSHOW WARNINGSSHUTDOWNSPLIT REGIONSTART TRANSACTIONTABLETRACETRUNCATEUPDATEUSEWITH
- Data Types
- Functions and Operators
- Overview
- Type Conversion in Expression Evaluation
- Operators
- Control Flow Functions
- String Functions
- Numeric Functions and Operators
- Date and Time Functions
- Bit Functions and Operators
- Cast Functions and Operators
- Encryption and Compression Functions
- Locking Functions
- Information Functions
- JSON Functions
- Aggregate (GROUP BY) Functions
- Window Functions
- Miscellaneous Functions
- Precision Math
- Set Operations
- List of Expressions for Pushdown
- TiDB Specific Functions
- Clustered Indexes
- Constraints
- Generated Columns
- SQL Mode
- Table Attributes
- Transactions
- Views
- Partitioning
- Temporary Tables
- Cached Tables
- Character Set and Collation
- Read Historical Data
- System Tables
mysql- INFORMATION_SCHEMA
- Overview
ANALYZE_STATUSCLIENT_ERRORS_SUMMARY_BY_HOSTCLIENT_ERRORS_SUMMARY_BY_USERCLIENT_ERRORS_SUMMARY_GLOBALCHARACTER_SETSCLUSTER_INFOCOLLATIONSCOLLATION_CHARACTER_SET_APPLICABILITYCOLUMNSDATA_LOCK_WAITSDDL_JOBSDEADLOCKSENGINESKEY_COLUMN_USAGEPARTITIONSPROCESSLISTREFERENTIAL_CONSTRAINTSSCHEMATASEQUENCESSESSION_VARIABLESSLOW_QUERYSTATISTICSTABLESTABLE_CONSTRAINTSTABLE_STORAGE_STATSTIDB_HOT_REGIONS_HISTORYTIDB_INDEXESTIDB_SERVERS_INFOTIDB_TRXTIFLASH_REPLICATIKV_REGION_PEERSTIKV_REGION_STATUSTIKV_STORE_STATUSUSER_PRIVILEGESVIEWS
- System Variables
- API Reference
- Storage Engines
- Dumpling
- Table Filter
- Troubleshoot Inconsistency Between Data and Indexes
- FAQs
- Release Notes
- Support
- Glossary
SHOW TABLE REGIONS
The SHOW TABLE REGIONS statement is used to show the Region information of a table in TiDB.
Syntax
SHOW TABLE [table_name] REGIONS [WhereClauseOptional];
SHOW TABLE [table_name] INDEX [index_name] REGIONS [WhereClauseOptional];
Synopsis
ShowTableRegionStmt:

TableName:
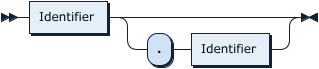
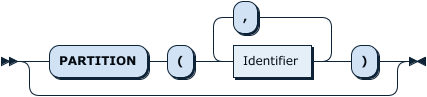
PartitionNameListOpt:
WhereClauseOptional:
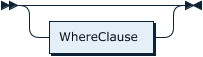
WhereClause:

Executing SHOW TABLE REGIONS returns the following columns:
REGION_ID: The Region ID.START_KEY: The start key of the Region.END_KEY: The end key of the Region.LEADER_ID: The Leader ID of the Region.LEADER_STORE_ID: The ID of the store (TiKV) where the Region leader is located.PEERS: The IDs of all Region replicas.SCATTERING: Whether the Region is being scheduled.1means true.WRITTEN_BYTES: The estimated amount of data written into the Region within one heartbeat cycle. The unit is byte.READ_BYTES: The estimated amount of data read from the Region within one heartbeat cycle. The unit is byte.APPROXIMATE_SIZE(MB): The estimated amount of data in the Region. The unit is megabytes (MB).APPROXIMATE_KEYS: The estimated number of Keys in the Region.
The values of WRITTEN_BYTES, READ_BYTES, APPROXIMATE_SIZE(MB), APPROXIMATE_KEYS are not accurate data. They are estimated data from PD based on the heartbeat information that PD receives from the Region.
Examples
Create an example table with enough data that fills a few Regions:
CREATE TABLE t1 (
id INT NOT NULL PRIMARY KEY auto_increment,
b INT NOT NULL,
pad1 VARBINARY(1024),
pad2 VARBINARY(1024),
pad3 VARBINARY(1024)
);
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM dual;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
SELECT SLEEP(5);
SHOW TABLE t1 REGIONS;
The output should show that the table is split into Regions. The REGION_ID, START_KEY and END_KEY may not match exactly:
...
mysql> SHOW TABLE t1 REGIONS;
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 94 | t_75_ | t_75_r_31717 | 95 | 1 | 95 | 0 | 0 | 0 | 112 | 207465 |
| 96 | t_75_r_31717 | t_75_r_63434 | 97 | 1 | 97 | 0 | 0 | 0 | 97 | 0 |
| 2 | t_75_r_63434 | | 3 | 1 | 3 | 0 | 269323514 | 66346110 | 245 | 162020 |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
3 rows in set (0.00 sec)
In the output above, a START_KEY of t_75_r_31717 and END_KEY of t_75_r_63434 shows that data with a PRIMARY KEY between 31717 and 63434 is stored in this Region. The prefix t_75_ indicates that this is the Region for a table (t) which has an internal table ID of 75. An empty key value for START_KEY or END_KEY indicates negative infinity or positive infinity respectively.
TiDB automatically rebalances Regions as needed. For manual rebalancing, use the SPLIT TABLE REGION statement:
mysql> SPLIT TABLE t1 BETWEEN (31717) AND (63434) REGIONS 2;
+--------------------+----------------------+
| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |
+--------------------+----------------------+
| 1 | 1 |
+--------------------+----------------------+
1 row in set (42.34 sec)
mysql> SHOW TABLE t1 REGIONS;
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 94 | t_75_ | t_75_r_31717 | 95 | 1 | 95 | 0 | 0 | 0 | 112 | 207465 |
| 98 | t_75_r_31717 | t_75_r_47575 | 99 | 1 | 99 | 0 | 1325 | 0 | 53 | 12052 |
| 96 | t_75_r_47575 | t_75_r_63434 | 97 | 1 | 97 | 0 | 1526 | 0 | 48 | 0 |
| 2 | t_75_r_63434 | | 3 | 1 | 3 | 0 | 0 | 55752049 | 60 | 0 |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
4 rows in set (0.00 sec)
The above output shows that Region 96 was split, with a new Region 98 being created. The remaining Regions in the table were unaffected by the split operation. This is confirmed by the output statistics:
TOTAL_SPLIT_REGIONindicates the number of newly split Regions. In this example, the number is 1.SCATTER_FINISH_RATIOindicates the rate at which the newly split Regions are successfully scattered.1.0means that all Regions are scattered.
For a more detailed example:
mysql> show table t regions;
+-----------+--------------+--------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| 102 | t_43_r | t_43_r_20000 | 118 | 7 | 105, 118, 119 | 0 | 0 | 0 | 1 | 0 |
| 106 | t_43_r_20000 | t_43_r_40000 | 120 | 7 | 107, 108, 120 | 0 | 23 | 0 | 1 | 0 |
| 110 | t_43_r_40000 | t_43_r_60000 | 112 | 9 | 112, 113, 121 | 0 | 0 | 0 | 1 | 0 |
| 114 | t_43_r_60000 | t_43_r_80000 | 122 | 7 | 115, 122, 123 | 0 | 35 | 0 | 1 | 0 |
| 3 | t_43_r_80000 | | 93 | 8 | 5, 73, 93 | 0 | 0 | 0 | 1 | 0 |
| 98 | t_43_ | t_43_r | 99 | 1 | 99, 100, 101 | 0 | 0 | 0 | 1 | 0 |
+-----------+--------------+--------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
6 rows in set
In the above example:
- Table t corresponds to six Regions. In these Regions,
102,106,110,114, and3store the row data and98stores the index data. - For
START_KEYandEND_KEYof Region102,t_43indicates the table prefix and ID._ris the prefix of the record data in table t._iis the prefix of the index data. - In Region
102,START_KEYandEND_KEYmean that record data in the range of[-inf, 20000)is stored. In similar way, the ranges of data storage in Regions (106,110,114,3) can also be calculated. - Region
98stores the index data. The start key of table t's index data ist_43_i, which is in the range of Region98.
To check the Region that corresponds to table t in store 1, use the WHERE clause:
test> show table t regions where leader_store_id =1;
+-----------+-----------+---------+-----------+-----------------+--------------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+--------------+------------+---------------+------------+----------------------+------------------+
| 98 | t_43_ | t_43_r | 99 | 1 | 99, 100, 101 | 0 | 0 | 0 | 1 | 0 |
+-----------+-----------+---------+-----------+-----------------+--------------+------------+---------------+------------+----------------------+------------------+
Use SPLIT TABLE REGION to split the index data into Regions. In the following example, the index data name of table t is split into two Regions in the range of [a,z].
test> split table t index name between ("a") and ("z") regions 2;
+--------------------+----------------------+
| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |
+--------------------+----------------------+
| 2 | 1.0 |
+--------------------+----------------------+
1 row in set
Now table t corresponds to seven Regions. Five of them (102, 106, 110, 114, 3) store the record data of table t and another two (135, 98) store the index data name.
test> show table t regions;
+-----------+-----------------------------+-----------------------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------------------------+-----------------------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| 102 | t_43_r | t_43_r_20000 | 118 | 7 | 105, 118, 119 | 0 | 0 | 0 | 1 | 0 |
| 106 | t_43_r_20000 | t_43_r_40000 | 120 | 7 | 108, 120, 126 | 0 | 0 | 0 | 1 | 0 |
| 110 | t_43_r_40000 | t_43_r_60000 | 112 | 9 | 112, 113, 121 | 0 | 0 | 0 | 1 | 0 |
| 114 | t_43_r_60000 | t_43_r_80000 | 122 | 7 | 115, 122, 123 | 0 | 35 | 0 | 1 | 0 |
| 3 | t_43_r_80000 | | 93 | 8 | 73, 93, 128 | 0 | 0 | 0 | 1 | 0 |
| 135 | t_43_i_1_ | t_43_i_1_016d80000000000000 | 139 | 2 | 138, 139, 140 | 0 | 35 | 0 | 1 | 0 |
| 98 | t_43_i_1_016d80000000000000 | t_43_r | 99 | 1 | 99, 100, 101 | 0 | 0 | 0 | 1 | 0 |
+-----------+-----------------------------+-----------------------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
7 rows in set
MySQL compatibility
This statement is a TiDB extension to MySQL syntax.